One major complexity of data migration projects is the data quality and data consistence – especially if several legacy environments are involved. A structured methodology and approach on data object definition, mapping and cleansing rules is needed. In this second part of our data migration series, we will take a closer look at the possibilities of the Talend data quality toolset with data migration projects.
Often there is a mismatch between estimations and impact of data migrations as part of bigger transformation projects: After evaluating and investing a significant amount of money into new systems, preparing data for a migration can often feel a little less exciting. Based on our experience, it is remarkable that data migration project budgets seem to be created based on the assumption of near to perfect data. And even if the cost of a data migration is probably only a fraction of the money spend on purchasing and implementing a new system – it is a key success factor to the overall project and adoption. Failing with data migration and data quality can multiply the costs and minimize the value of any project for your organization. Therefore, in terms of data migration thorough analysis, appropriate planning, early involvement of stakeholders and ownership from across different business areas are keys to success.
Determining data quality to begin with
Migrating data from one or more applications to others means to look at objects, data model, structure of data, definitions, etc. Those tasks could even be more complex due to data quality issues that almost always exist in legacy systems. So actually, most data migration projects turn out to be data quality projects and also deliver a chance to setup a future-proof data governance strategy alongside the migration efforts.
Data Quality Audits – Know your starting point
Beside an inventory (data sources and objects to be migrated, their dictionary and data model) and a volume estimate, an early quick check on the data quality can help to create a realistic estimate on your migration efforts. Already at an early stage of your project, start profiling the data in your legacy systems. At this stage, you might not have access to a mature design for the target system and might not be able to focus on the specific data requirements of your new system. Nevertheless, you should already know that certain (master) data objects like customer information, product attributes, etc. will be in scope and an early quality audit of the legacy system can be further detailed and enhanced during future project iterations.
Talend Data Quality
With a complete toolset of data quality components, Talend can support a migration project right away from the start.
- Data profiling allows you to create data quality reports and to analyze your legacy data and create already initial insides on the data quality by conducting a full-volume analysis.
- Define data cleansing, matching and consolidation rules prevent you from moving dirty data into the new systems. Automatic matching algorithms and machine learning can be used to determine duplicates, golden records and apply survivorship rules.
- Business ownership and governance on data quality can be supported by using applications like the data stewardship console and data prep tooling – allowing users to work in an Excel like toolset to check and cleanse suspect records in combination with automated cleansing rules.
- Logging of cleansing and transformation actions can be used to generate an overall audit trail for your migration project to track the progress and fulfill compliancy rules
Examples out of our daily practice
One of the use cases we have worked on recently is the consolidation of a product hierarchy across various legacy applications. The challenge was to create a mapping of local variations to a global hierarchy model with cleansed product master data applied for consolidated reporting.Each product (item) needs to be mapped to the Master hierarchy. To simplify the case, we will start with a simple 2-level hierarchy, where mapping needs to be carried out for each category present in the data.
Example: Product Master Data Consolidation
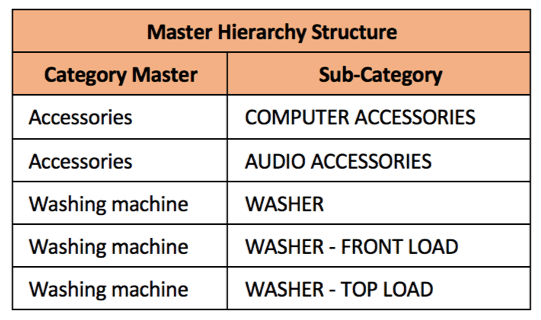 |
Let’s look at a simple master hierarchy structure for product categories. |
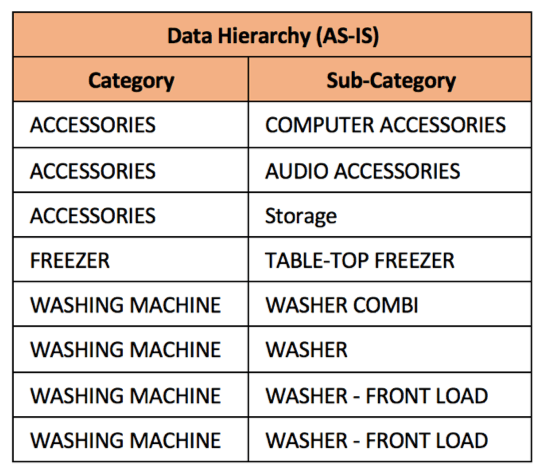 |
Compared with another product hierarchy existing in one of the legacy applications, differences are easy to spot. |
| The hierarchy mapping is carried out and marks out the missing / unmapped entries compared with the master hierarchy: | |
 |
|
The “UNMAPPED” represents the one (Category or Sub-Category) that are not present in the Master hierarchy structure. Those unmapped fields need to be validated by functional data owners (SMEs / Data Stewards).
Preparation steps involved
- Identify distinct Category/ Sub-Category combinations from the data sources
- Manually map the product hierarchy from the data source with that of the Master structure
Using Talend Data Integration (DI), the “UNMAPPED” data hierarchy was exposed to Talend Data Stewardship (TDS) Console
- The SMEs or Data Stewards have to ensure that a valid category (and sub-category) gets populated in place of the “UNMAPPED” ones
- The Stewards validate the hierarchy and resolve issues by tagging a valid category / sub-category
- Once the hierarchy mapping is completed in the TDS console, the next step is to update the target data to hold the correct / latest hierarchy using Talend DI again.
|
|
|


Product Data Analysis – Discrepancy & Golden Records Identification
Beside the cleaning-up of the product hierarchy,also product master data attributes present in the data source need to be validated for Data Quality. The data should be classified in to the following discrepancy classification:
- NULL fields
- Duplicates (Numeric/ Reference attribute)
- Invalids (specific to attributes such as barcodes/ GTIN)
- Duplicates based on product description (the description might be different but the product in reference might be the same)
Starting point is the creation of a unique identifier per record to create an audit trail for any modifications, consolidations and transformations. A sequential ID for each record is sufficient to easily identify them later. Using Talend DI and DQ components, source data is replicated into multiple streams to perform similar operations across multiple attributes:
- Identify NULL values
- Identify attribute level duplicates by grouping the data by the attribute value & by filtering the data having more than 1 instance for the same attribute value
- Validate standardized identifiers like barcodes:
- NULLs
- Duplicates
- Invalids (e.g. based on length, non-numeric characters, incorrect check digits)
- Patterns (DQ Profiling perspective)
- Consolidate discrepancies for all attributes.
- Creation of additional columns / attributes to identify:
- Discrepancy Type (NULLs, Invalid, Duplicate)
- Discrepancy Attribute/ Field (Attribute in-scope for that specific data row)
- Mapping of the product hierarchy master to the discrepancy table for reporting and statistics
Golden Record Identification
- Compare input sources against identified discrepancies to filter out the remaining records. These remaining records/ data needs to be analyzed further.
- Identify duplicates based on product description
- Using integrated fuzzy logic and algorithms with Talend DQ
- Segregate the unique, duplicate and suspect records accordingly
- Merge duplicates
- Suspect records will be provided to data stewards to further analysis. Feedback is also used to modify and finetune the algorithms used for deduplication.
- Unique records that did not fall under any discrepancies and hence are classified as “Golden Records”
Reporting
During all processing steps, operations are logged on record level. The resulting log tables can be easily queried to come up with multiple reporting formats. Since all output data is mapped against the master product hierarchy statistics can easily be broken down on country, legacy system or category / sub-category level to determine the data quality on a granular level.
This is a single simplified example out of our daily practice. Most important for us is to create a migration framework than can not only be used one-off bust also transferred into a governed new environment to keep data clean and in-sync.
Data Governance: Maintaining data quality post-migration
Data quality is an ongoing effort. After making substantial investments to ensure high quality data is entered into your new systems, there is a good opportunity to put data quality processes in place to leverage the migration efforts. Governing data maintenance and monitoring data moving between different systems allows you to maintain control. If you plan to invest in a data quality tooling to help complete your migration, make sure monitoring and reporting capabilities are included to keep up your data quality post-migration.